背景
rnn可以解决时序问题,但是容易出现梯度爆炸/梯度爆炸的问题,当文本较长的时候,效果并不好。LSTM,是Long Short-Term Memory,中文可以理解成比较长的Short-Term Memory,因为当文本非常长的时候,效果也会有问题(可以通过加入attention方式解决)。
介绍
具体网络结构
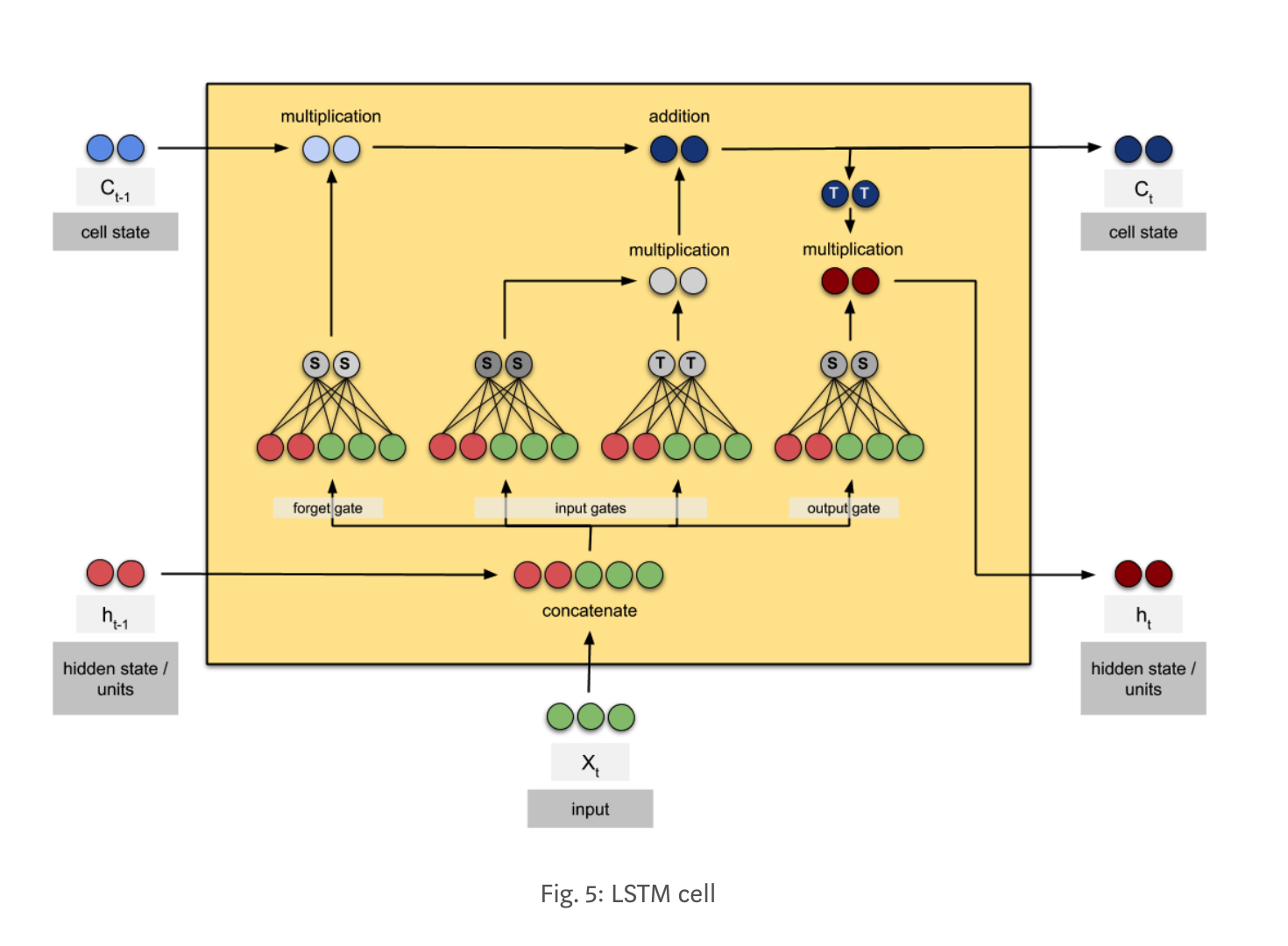
下面这张图,是目前我看到的最清晰的描述LSTM网络结构的图片,使用一个实例描述了整个过程。其中S表示该神经元使用sigmoid激活函数触发,T表示该神经元使用tanh函数触发。输入的纬度是3,隐层的纬度是2。
抽象网络结构
下面这张图画的也很不错,从抽象的角度定义了LSTM,可以对比来看,一个是抽象,一个是实例。
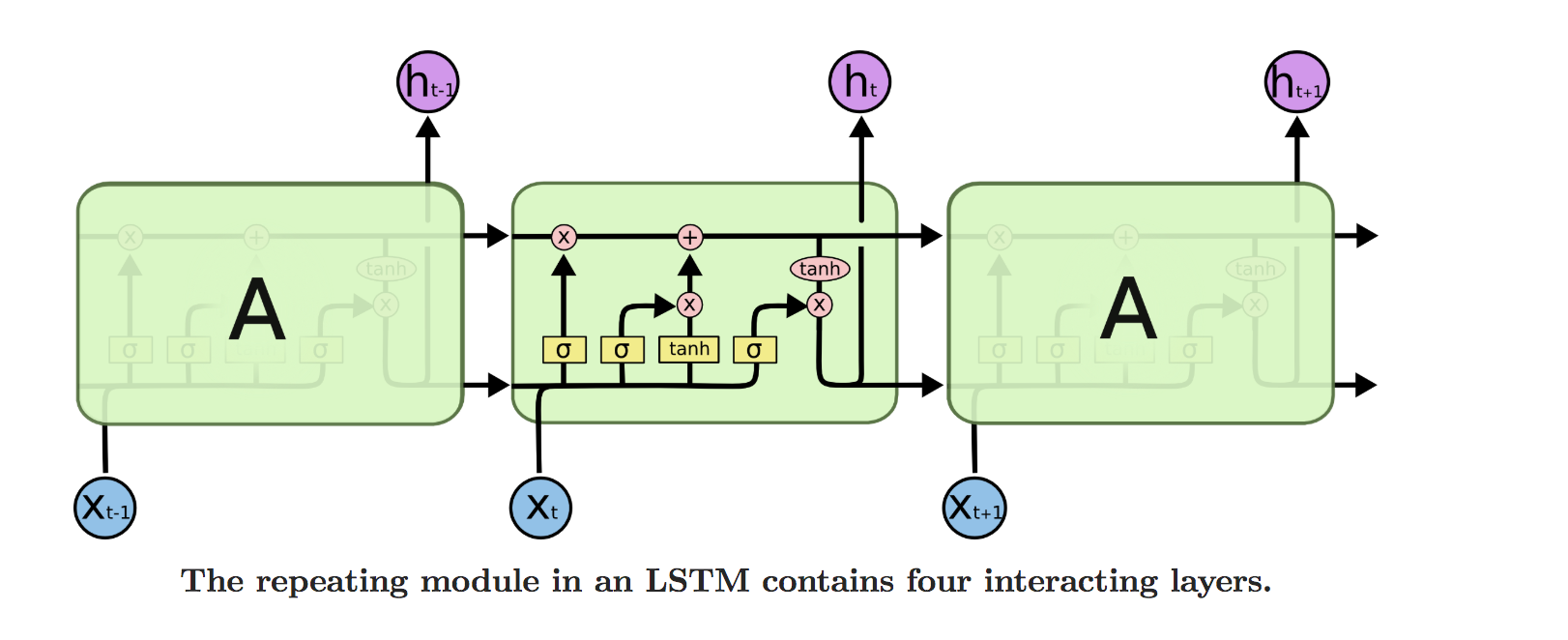
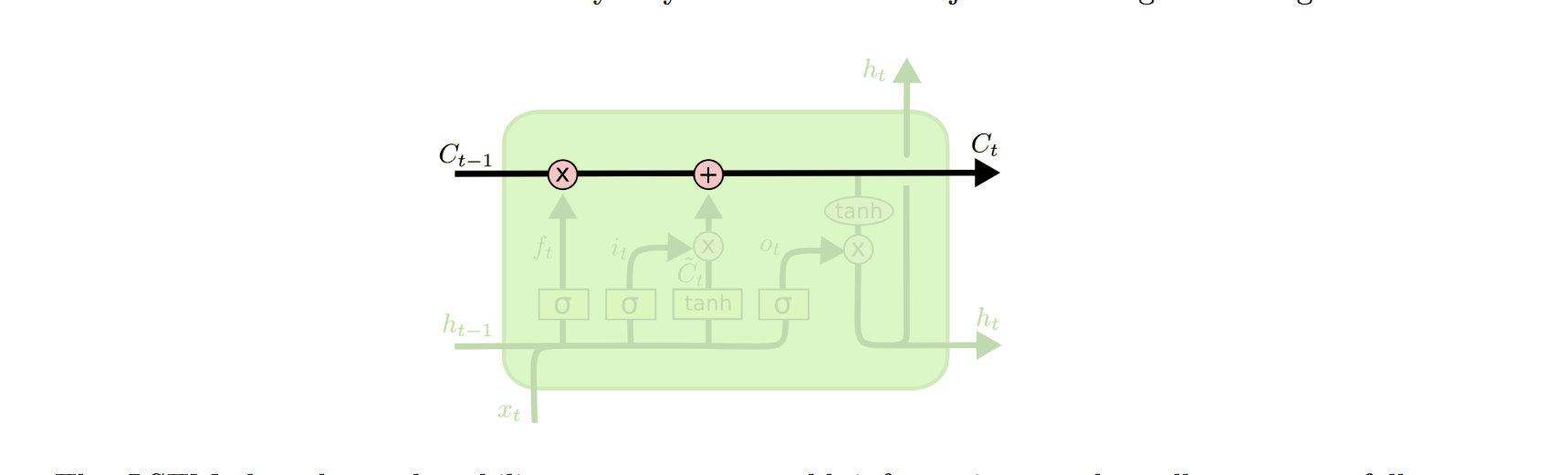
几个公式:
- 遗忘门:$f_t = \sigma(W_f [h_{t-1}, x_t] + b_f)$
- 输入门:$i_t = \sigma(W_i[h_{t-1}, x_t] + b_i)$
- $\tilde{C_t} = tanh(W_C [h_{t-1}, x_t] + b_C)$
- $C_t = f_t C_{t - 1} + i_t \tilde {C_t}$
- $O_t = \sigma(W_o[h_{t-1}, x_t] + b_o)$
- $h_t = o_t * tanh(C_t)$
相关代码
下面代码构造网络参数,我们可以看出来_kernel用来存储模型参数,可以看出来存储了4倍的参数,因为我们有四个FFC网络。
1 | def build(self, inputs_shape): |
下面这段代码是实际的计算过程,需要注意的是,每次更新,需要返回两个状态$h_t$和$C_t$。
1 | def call(self, inputs, state): |