最近,在学习fasttext相关源码,这篇文章主要分享下学习监督学习相关的学习心得。
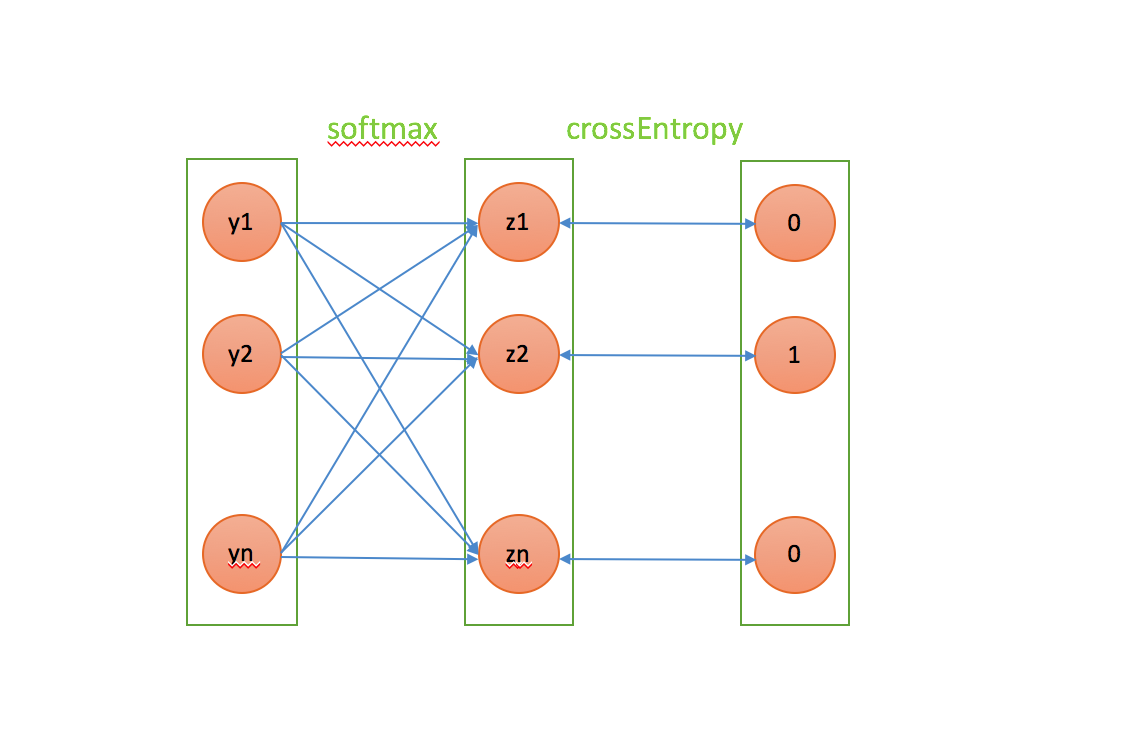
主要架构

- 输入:term级别词向量,比如输入“中国” “新” “说唱”三个term,每个词进入系统前都被随机初始化成了dim纬度的向量
- hidden : 将所有term的向量进行相加,然后求解平均值,组成短片段的向量表示
- 输出:label个向量, 即我们要分类的个数
- 对输出对值求softmax,loss函数使用crossEntroy loss
求解的参数
和传统lr的区别是:传统lr我们是知道特征的值的,只需要求解w的值;但是,这里我们词向量也是未知的,也是需要求解的, 因此需要求解的参数是以下两个:
- hidder layer和最终输出的矩阵权重w
- 每个单词的词向量
理论基础
crossEntropy loss梯度
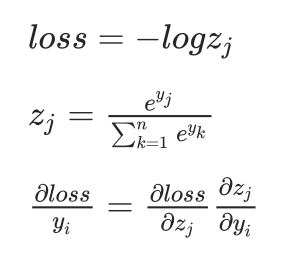
求解梯度
当i == j时:
求解梯度
当i != j时:
结合代码分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15real Model::softmax(int32_t target, real lr) {
grad_.zero();
computeOutputSoftmax();
for (int32_t i = 0; i < osz_; i++) {
//alpha就是loss对softmax之前变量梯度的计算
//如果i == target, 梯度为output[i] - label
//如果i != target, 梯度为output[i]
//这儿用的label - ouput[i], 因为减去梯度,相当于加上负梯度
real label = (i == target) ? 1.0 : 0.0;
real alpha = lr * (label - output_[i]);
grad_.addRow(*wo_, i, alpha);
wo_->addRow(hidden_, i, alpha);
}
return -log(output_[target]);
}举例
如果类别一共三维,经过softmax后的向量为[0.1, 0.3, 0.6], 第二维label为1,则loss对原始输入的梯度为[0.1, -0.7, 0.6], 可见需要在第二维上重点调整,以调到最大。